

Browser caching mechanism


Cache can be said to be a simple and efficient optimization method in performance optimization. It can significantly reduce the loss caused by network transmission. For a data request, it can be divided into three steps: initiating a network request, back-end processing, and browser response. Browser caching can help us optimize performance in the first and third steps. For example, if the cache is used directly without initiating a request, or the request is initiated but the data stored in the back-end is consistent with the front-end, then there is no need to send the data back, thus reducing the response data.
In the following content, we will explore the browser caching mechanism through the following parts:
- Cache location
- Caching strategy
- Application of caching strategies in actual scenarios
Cache location
From the cache location, there are four types, and each has a priority. When the cache is searched in turn and none of them is hit, the network will be requested.
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
- Network request
Service Worker
Service Worker's caching is different from other built-in caching mechanisms in browsers. It allows us to freely control which files are cached, how to match the cache, how to read the cache, and the cache is continuous.
When the Service Worker does not hit the cache, we need to call the fetch function to get the data. In other words, if we do not hit the cache in the Service Worker, we will look up the data according to the cache lookup priority. But no matter whether we get the data from the Memory Cache or from the network request, the browser will show that we get the content from the Service Worker.
Memory Cache
Memory Cache is also the cache in memory. Reading data in memory is definitely faster than disk. However, although the memory cache is efficient to read, the cache persistence is very short and will be released as the process is released. Once we close the Tab page, the cache in memory is released.
After we visit the page, refresh the page again, we can find that a lot of data comes from the memory cache
So since the memory cache is so efficient, can we store all the data in the memory?
Let me talk about the conclusion first, this is impossible. First of all, the memory in the computer must be much smaller than the capacity of the hard disk. The operating system needs to carefully plan the use of memory, so the memory that we can use must not be much. In fact, most of the files can be stored in the memory, such as JSS, HTML, CSS, pictures, and so on. But the process of which files the browser will put into the memory is very metaphysical, and I have checked a lot of information and have not reached a conclusion.
Of course, I have also drawn some conclusions through some practice and guessing:
- For large files, the high probability is not stored in the memory, and vice versa.
- If the current system memory usage is high, the files will be stored in the hard disk first
Disk Cache
Disk Cache is the cache stored in the hard disk. The reading speed is slower, but everything can be stored in the disk. Compared with Memory Cache, it is better than Memory Cache
in terms of capacity and storage timeliness. Among all browser caches, Disk Cache basically has the largest coverage. It will determine which resources need to be cached according to the fields in HTTP Herder, which resources can be used directly without request, and which resources have expired and need to be requested again. And even in the case of cross-sites, once the resources of the same address are cached by the hard disk, they will not request data again.
Caching strategy
Generally, browser caching strategies are divided into two types: strong caching and negotiated caching, and caching strategies are implemented by setting HTTP Header.
Strong cache
Strong caching can be achieved by setting two HTTP Headers: Expires and Cache-Control. Strong caching means that no request is required during caching, and the state code is 200.
Expires
Expires is a product of HTTP/1, which means that the resource will expire after Wed, 22 Oct 2018 08:41:00 GMT and needs to be requested again. And Expires is limited by the local time. If the local time is modified, the cache may become invalid.
Cache-control
Cache-control: max-age=30
Cache-Control appeared in HTTP/1.1 and has a higher priority than Expires. The value of this attribute indicates that the resource will expire after 30 seconds and needs to be requested again.
Cache-Control can be set in the request header or response header, and can be used in combination with a variety of instructions
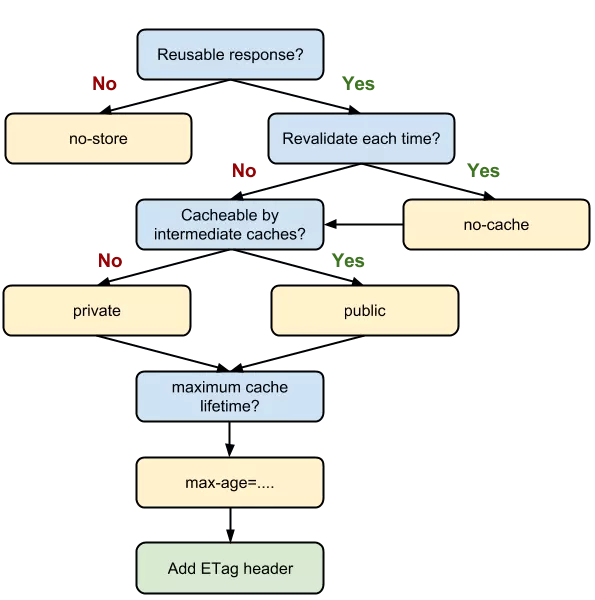
As we can see from the figure, we can use multiple instructions together to achieve multiple goals. For example, we hope that resources can be cached, and both the client and proxy server can be cached, and the cache expiration time can also be set. Next we will learn the role of some common instructions
Negotiation cache If the cache expires, you need to initiate a request to verify whether the resource has been updated. Negotiation caching can be achieved by setting two HTTP Headers: Last-Modified and ETag.
When the browser initiates a request to verify the resource, if the resource has not been changed, the server will return a 304 status code and update the browser cache validity period.
Last-Modified represents the last modification date of the local file. If-Modified-Since will send the value of Last-Modified to the server, and ask the server whether the resource has been updated after this date. If there is an update, the new resource will be sent back, otherwise A 304 status code is returned.
Application of caching strategies in actual scenarios
It is meaningless to simply understand the theory without putting it into practice. Next, let's learn how to use these theories through a few scenarios.
Frequently changing resources For frequently changing resources, you first need to use Cache-Control: no-cache to make the browser request the server every time, and then use ETag or Last-Modified to verify whether the resource is valid. Although this approach cannot save the number of requests, it can significantly reduce the size of the response data.
Code file
This specifically refers to code files other than HTML, because HTML files are generally not cached or the cache time is very short. Generally speaking, tools are now used to package code, then we can hash the file name, and only when the code is modified will a new file name be generated. Based on this, we can set the cache validity period for the code file for one year Cache-Control: max-age=31536000, so that only when the file name introduced in the HTML file is changed will the latest code file be downloaded, otherwise it will be used all the time Cache.